1 概述
UE采用多线程渲染,通过剖析其渲染框架,对深入渲染流程大有裨益。
相关名词:
-
RHI: 渲染硬件层接口(Render Hardware Interface),UE4的源码里经常出现RHI,详细说明可参考文章:UE4 RHI浅析
-
Draw Call: 指CPU向GPU发出的一次渲染指令,让GPU绘制指定的几何体(GPU逐个Draw Call 进行渲染),发生在几何阶段。
-
Feature Level: 特性层级,各渲染硬件层接口(RHI)都限定不同版本的图形API所支持的特性集合。例如,SM4是DX10 Shader Model 4所支持的特性集合,还有SM5、ES2等等。
2 UE4 渲染器示例(SlateViewer)
麻雀虽小,五脏俱全,通过SlateViewer来窥探一下UE4的简单渲染流程。
打开UE4引擎的VS工程,将Program下的SlateViewer设置为启动项,编译运行,可以显示一个单独的程序,如下:
通过SlateViewer研究一下UE4的简单渲染器。
单线程渲染,看打SlateView代码进行分析。
初始化流程
初始化流程始于InitializeAsStandaloneApplication函数,我们关注到最终CreateProgram函数,该函数完成Shader的链接与编译。
void FSlateOpenGLRenderingPolicy::ConditionalInitializeResources()
{
if( !bIsInitialized )
{
// 创建并编译Shader
VertexShader.Create( FString::Printf( TEXT("%sShaders/StandaloneRenderer/OpenGL/SlateVertexShader.glsl"), *FPaths::EngineDir() ) );
PixelShader.Create( FString::Printf( TEXT("%sShaders/StandaloneRenderer/OpenGL/SlateElementPixelShader.glsl"), *FPaths::EngineDir() ) );
// 链接Shader程序
ElementProgram.CreateProgram( VertexShader, PixelShader );
// 创建默认贴图
check( WhiteTexture == NULL );
WhiteTexture = TextureManager->CreateColorTexture( TEXT("DefaultWhite"), FColor::White );
}
}
SlateViewer使用的是引擎Shaders/StandaloneRenderer目录下的两个Shader文件,根据平台可使用OpenGL或D3D目录下的Shader文件,XP以上的Windows系统会使用D3D,否则使用OpenGL。这里以OpenGL为例:
创建顶点和像素着色器里会调用CompileShader函数进行编译,内部就是OpenGL的常见调用,编译流程如下:
void FSlateOpenGLShader::CompileShader( const FString& Filename, GLenum ShaderType )
{
//生成ShaderID,类型为顶点或像素着色器
ShaderID = glCreateShader( ShaderType );
GLint CompileStatus = GL_FALSE;
check( ShaderID );
//加载Shader文件
bool bFileFound = FFileHelper::LoadFileToString( Source, *Filename );
//向OpenGl传入源码(Chars是做了格式化字符,过程省略)
glShaderSource( ShaderID, 2, (const ANSICHAR**)Chars, NULL );
//编译Shader
glCompileShader( ShaderID );
//获取编译状态,
glGetShaderiv( ShaderID, GL_COMPILE_STATUS, &CompileStatus );
if( CompileStatus == GL_FALSE )
{
//编译失败则移除Shader.
glDeleteShader( ShaderID );
ShaderID = 0;
}
}
至此,我们完成了Shader的创建与编译。接下来,通过CreateProgram将着色器程序与Shader链接。
void FSlateOpenGLShaderProgram::LinkShaders( const FSlateOpenGLVS& VertexShader, const FSlateOpenGLPS& PixelShader )
{
//创建着色器程序
ProgramID = glCreateProgram();
//向着色器程序上添加顶点与像素着色器
glAttachShader( ProgramID, VertexShaderID );
glAttachShader( ProgramID, PixelShaderID );
//将用户定义属性变量与通用顶点属性索引相关联,自定义变量名定义在Shader中。
glBindAttribLocation(ProgramID, 0, "InTexCoords");
glBindAttribLocation(ProgramID, 1, "InPosition");
glBindAttribLocation(ProgramID, 4, "InColor");
//链接程序与Shader
glLinkProgram( ProgramID );
//获取链接状态
glGetProgramiv( ProgramID, GL_LINK_STATUS, &LinkStatus );
if( LinkStatus == GL_FALSE )
{
// Linking failed, display why.
FString Log = GetGLSLProgramLog( ProgramID );
checkf(false, TEXT("Failed to link GLSL program: %s"), *Log );
}
}
渲染流程
在FSlateApplication类的Tick中,每帧进行渲染,我们关注最终的DrawWindow函数:
void FSlateOpenGLRenderer::DrawWindows( FSlateDrawBuffer& InWindowDrawBuffer )
{
// 按批次绘制
for( int32 ListIndex = 0; ListIndex < WindowElementLists.Num(); ++ListIndex )
{
FSlateWindowElementList& ElementList = *WindowElementLists[ListIndex];
if ( ElementList.GetWindow().IsValid() )
{
//更新顶点Buffer
RenderingPolicy->UpdateVertexAndIndexBuffers( BatchData );
//OpenGL创建视口
glViewport( Viewport->ViewportRect.Left, Viewport->ViewportRect.Top, Viewport->ViewportRect.Right, Viewport->ViewportRect.Bottom );
//绘制一个批次的元素,里面会执行一次DrawCall
RenderingPolicy->DrawElements( ViewMatrix*Viewport->ProjectionMatrix, WindowSize, BatchData.GetRenderBatches(), BatchData.GetRenderClipStates() );
}
}
}
主要渲染流程在DrawElements函数里面:
void FSlateOpenGLRenderingPolicy::DrawElements( const FMatrix& ViewProjectionMatrix, FVector2D ViewportSize, const TArray<FSlateRenderBatch>& RenderBatches, const TArray<FSlateClippingState> RenderClipStates)
{
// 绑定顶点缓冲(即VBO),每个元素共享顶点Buffer
VertexBuffer.Bind();
//绑定着色器程序,每个元素使用相同着色器程序,内部调用glUseProgram( ProgramID )
ElementProgram.BindProgram();
//设定视图投影矩阵
ElementProgram.SetViewProjectionMatrix( ViewProjectionMatrix );
//关闭深度测试和剪面(深度测试用于选择性渲染片元,剪面即所有的不是正面朝向的面都会被丢弃)
glDisable(GL_DEPTH_TEST);
glDisable(GL_CULL_FACE);
//设置透明度测试
#if !PLATFORM_USES_ES2 && !PLATFORM_LINUX
glEnable(GL_ALPHA_TEST);
glAlphaFunc( GL_GREATER, 0.0f );
#endif
//设置颜色混合,比如透过一块红色的玻璃去看一个绿色的球时,此时就会发生颜色的混合现象
glBlendFunc( GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA );
glBlendEquation( GL_FUNC_ADD );
//设置模板测试参数,模板测试用于过滤某些片元(模板测试是在深度测试之前进行的,可以作为一种丢弃片元的辅助方法)
glStencilMask(0xFF);
glStencilFunc(GL_GREATER, 0, 0xFF);
glStencilOp(GL_KEEP, GL_INCR, GL_INCR);
//绘制批次数据
int32 LastClippingIndex = -1;
for( int32 BatchIndex = 0; BatchIndex < RenderBatches.Num(); ++BatchIndex )
{
...
//是否开启颜色混合,当需要绘制半透明像素时,才采用混合操作。
if( EnumHasAllFlags(DrawFlags, ESlateBatchDrawFlag::NoBlending) )
{
glDisable( GL_BLEND );
}
else
{
glEnable( GL_BLEND );
}
// 是否开启模板测试
glDisable(GL_STENCIL_TEST);
if( RenderBatch.ShaderType == ESlateShader::LineSegment )
{
// Test that the pixels in the line segment have only been drawn once
glEnable(GL_STENCIL_TEST);
}
//为每个顶点设置顶点buffer的偏移量
glEnableVertexAttribArray(0);
Offset = STRUCT_OFFSET( FSlateVertex, TexCoords );
glVertexAttribPointer( 0, 4, GL_FLOAT, GL_FALSE, Stride, BUFFER_OFFSET(Stride*BaseVertexIndex+Offset) );
glEnableVertexAttribArray(1);
Offset = STRUCT_OFFSET( FSlateVertex, Position );
glVertexAttribPointer( 1, 2, GL_FLOAT, GL_FALSE, Stride, BUFFER_OFFSET(Stride*BaseVertexIndex+Offset) );
glEnableVertexAttribArray(4);
Offset = STRUCT_OFFSET( FSlateVertex, Color );
glVertexAttribPointer( 4, 4, GL_UNSIGNED_BYTE, GL_TRUE, Stride, BUFFER_OFFSET(Stride*BaseVertexIndex+Offset) );
//绑定索引缓冲(即EBO),在绘制图形的过程中,顶点可能会重复。
//比如两个三角形组成了四边形,那么,必然有两个点是重复的。因此采用索引的方式,四个点即可描述四边形。
IndexBuffer.Bind();
//裁剪测试
if (RenderBatch.ClippingIndex != LastClippingIndex)
{
LastClippingIndex = RenderBatch.ClippingIndex;
if (RenderBatch.ClippingIndex != -1)
{
const FSlateClippingState& ClipState = RenderClipStates[RenderBatch.ClippingIndex];
if (ClipState.ScissorRect.IsSet())
{
const FSlateClippingZone& ScissorRect = ClipState.ScissorRect.GetValue();
glEnable(GL_SCISSOR_TEST);
const float ScissorWidth = FVector2D::Distance(ScissorRect.TopLeft, ScissorRect.TopRight);
const float ScissorHeight = FVector2D::Distance(ScissorRect.TopLeft, ScissorRect.BottomLeft);
glScissor(ScissorRect.TopLeft.X, ViewportSize.Y - ScissorRect.BottomLeft.Y, ScissorWidth, ScissorHeight);
}
else
{
// We don't support stencil clipping on the d3d rendering policy.
glDisable(GL_SCISSOR_TEST);
}
}
else
{
glDisable(GL_SCISSOR_TEST);
}
}
//最终绘制元素,此处有一个DrawCall
#if PLATFORM_USES_ES2
glDrawElements(GetOpenGLPrimitiveType(RenderBatch.DrawPrimitiveType), RenderBatch.NumIndices, GL_INDEX_FORMAT, (void*)StartIndex);
#else
// Draw all elements in batch
glDrawRangeElements( GetOpenGLPrimitiveType(RenderBatch.DrawPrimitiveType), 0, RenderBatch.NumVertices, RenderBatch.NumIndices, GL_INDEX_FORMAT, (void*)(PTRINT)StartIndex );
#endif
}
//清除缓冲
glDisable(GL_SCISSOR_TEST);
glActiveTexture( GL_TEXTURE0 );
glBindTexture( GL_TEXTURE_2D, 0 );
glUseProgram(0);
}
OpenGL测试的顺序是:剪裁测试、Alpha测试、模板测试、深度测试。如果某项测试不通过,则不会进行下一步,而只有所有测试都通过的情况下才会执行混合操作。
如果所有的像素都是“透明”或“不透明”,没有“半透明”时,应该尽量采用Alpha测试而不是采用混合操作。当需要绘制半透明像素时,才采用混合操作。
Shader分析:
SlateVertexShader:
void main()
{
TexCoords = InTexCoords;
Color.rgb = sRGBToLinear(InColor.rgb);
Color.a = InColor.a;
Position = vec4( InPosition, 0, 1 );
//坐标变换, ViewProjectionMatrix由UE层传递过来。
gl_Position = ViewProjectionMatrix * vec4( InPosition, 0, 1 );
}
SlateElementPixelShader:
void main()
{
vec4 OutColor;
if( ShaderType == ST_Default ){ OutColor = GetDefaultElementColor();}
else if( ShaderType == ST_Border ){ OutColor = GetBorderElementColor();}
else if( ShaderType == ST_Font ){ OutColor = GetFontElementColor(); }
else{ OutColor = GetSplineElementColor(); }
// gamma校正,亮度调节
OutColor.rgb = GammaCorrect(OutColor.rgb);
if( EffectsDisabled )
{
//desaturate
vec3 LumCoeffs = vec3( 0.3, 0.59, .11 );
float Lum = dot( LumCoeffs, OutColor.rgb );
OutColor.rgb = mix( OutColor.rgb, vec3(Lum,Lum,Lum), .8 );
vec3 Grayish = vec3(0.4, 0.4, 0.4);
OutColor.rgb = mix( OutColor.rgb, Grayish, clamp( distance( OutColor.rgb, Grayish ), 0.0, 0.8) );
}
//最终输出片元颜色
gl_FragColor = OutColor.bgra;
}
OpenGL总渲染流程:
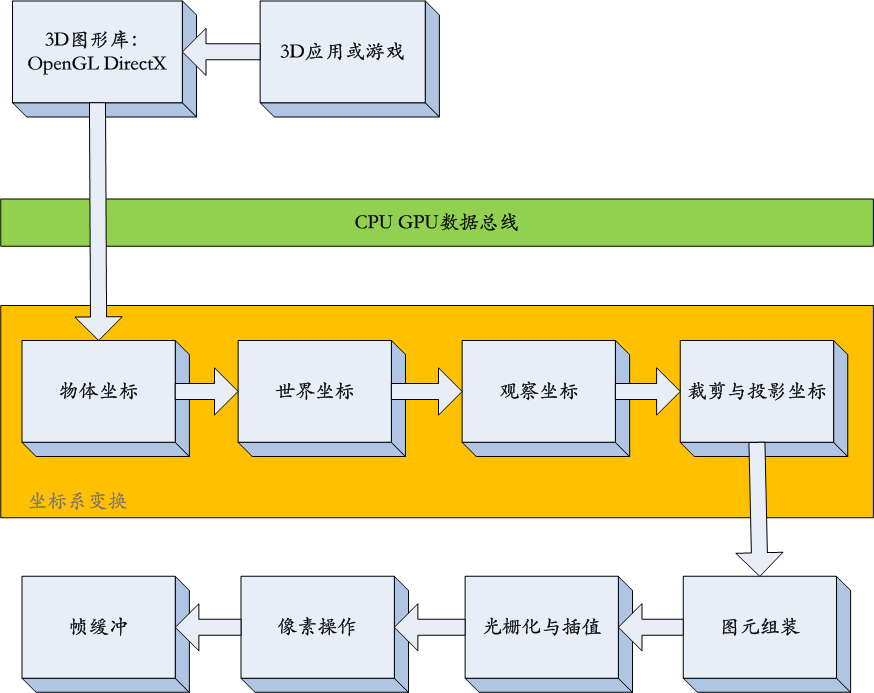
渲染管线各阶段流程:
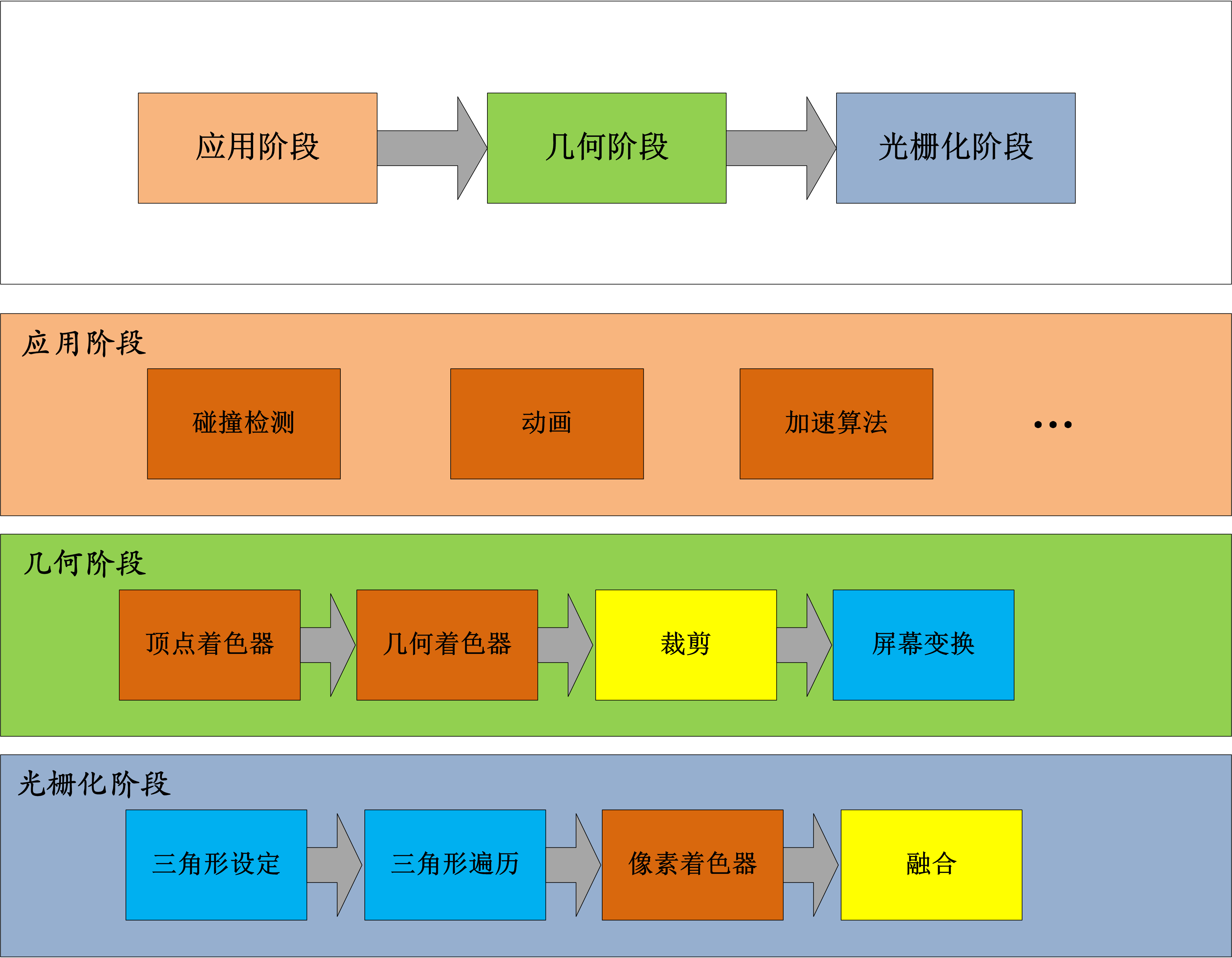
说明:
-
红色:完全可编程(几何着色器为可选)
-
黄色:可配置不可编程
-
蓝色:完全固定
-
之前程序中的各种测试(模板测试、深度测试)在融合阶段执行。
3 UE4 渲染线程
3.1 多线程渲染框架
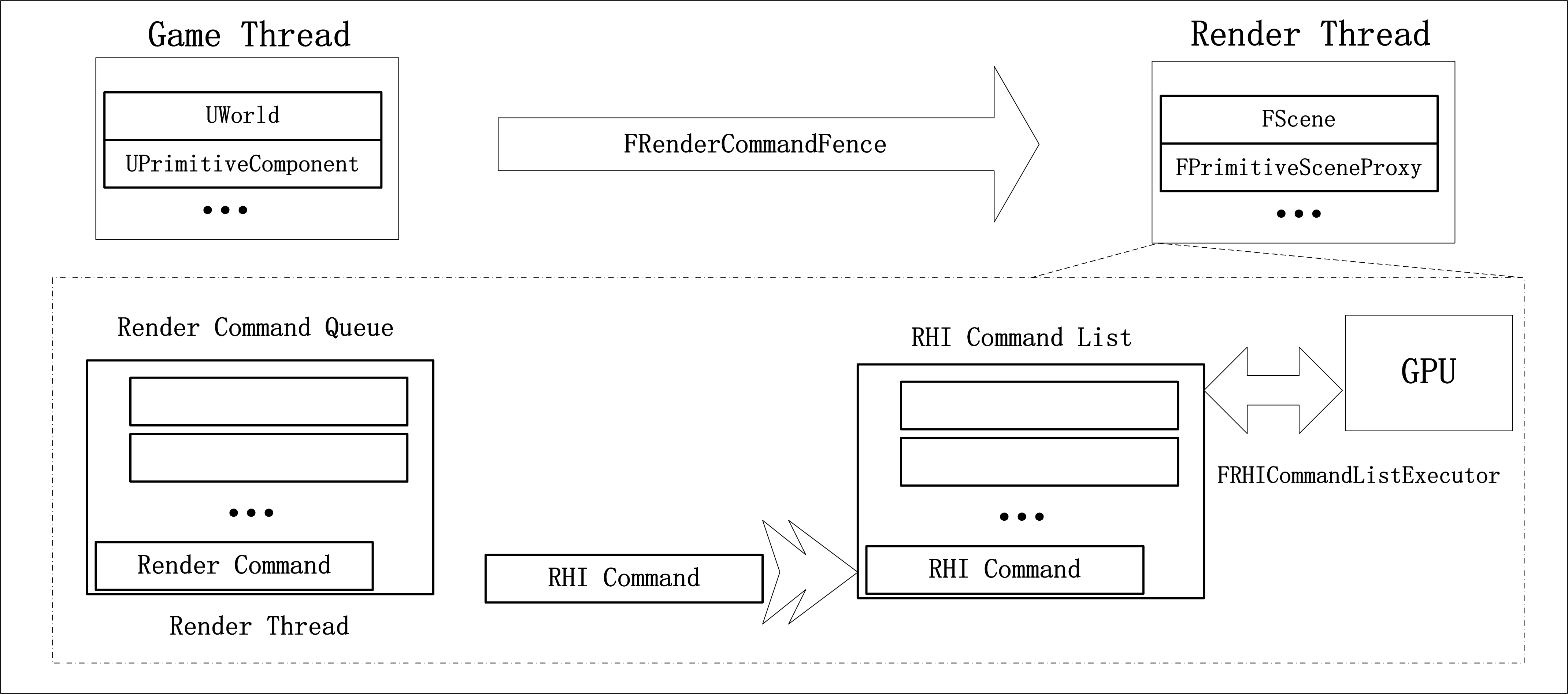
UE4渲染线程结构如下图所示。
-
UE4通过StartRenderingThread函数创建渲染线程,并注册相应的渲染任务线程,渲染命令会在任务线程中执行。
FTaskGraphInterface::Get().AttachToThread(ENamedThreads::RenderThread)
渲染任务线程与渲染线程并行,并受渲染线程支配。
-
FPrimitiveSceneProxy是UPrimitiveComponent在渲染线程的代理,一般会成对出现,如UCableComponent/FCableSceneProxy。
-
游戏主线程调用渲染指令,渲染指令会被放入TashGraph系统渲染任务线程的执行队列。
-
为了实现多线程渲染,UE4引入了RHI线程,渲染指令最终会调用RHI指令,RHI指令放入指令列表底部,RHI线程会从指令列表顶部取指令发送给GPU并等待GPU结果(指令队列先进先出)。
-
FFrameEndSync的Sync函数实现游戏主线程和渲染线程的同步,FRenderCommandFence通过BeginFence将一个结束事件插入渲染队列最后,通过Wait函数让游戏线程等待结束事件执行完成(即所有渲染指令执行完成),否则阻塞游戏线程。
并行渲染:
对于支持并行渲染的平台(DX12/Vulkan/Metal),UE4通过FParallelCommandListSet并行派发的RHI指令。不同Pass会派生不同的FParallelCommandListSet,可查看对应的派生类,Pass间也是并行的。渲染管线会包含多个渲染通道(BassPass/LightPass等),每个通道负责不同的任务。
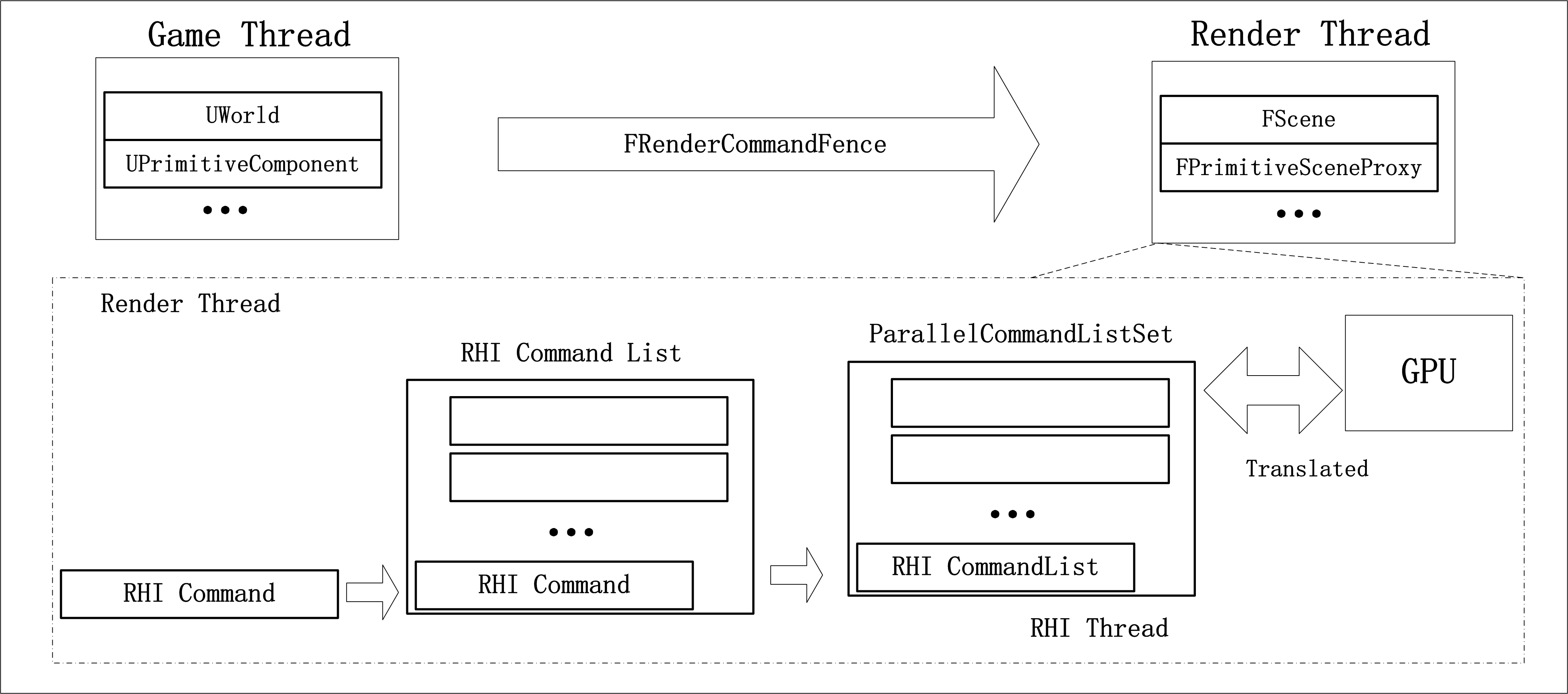
并行渲染任务拆分:
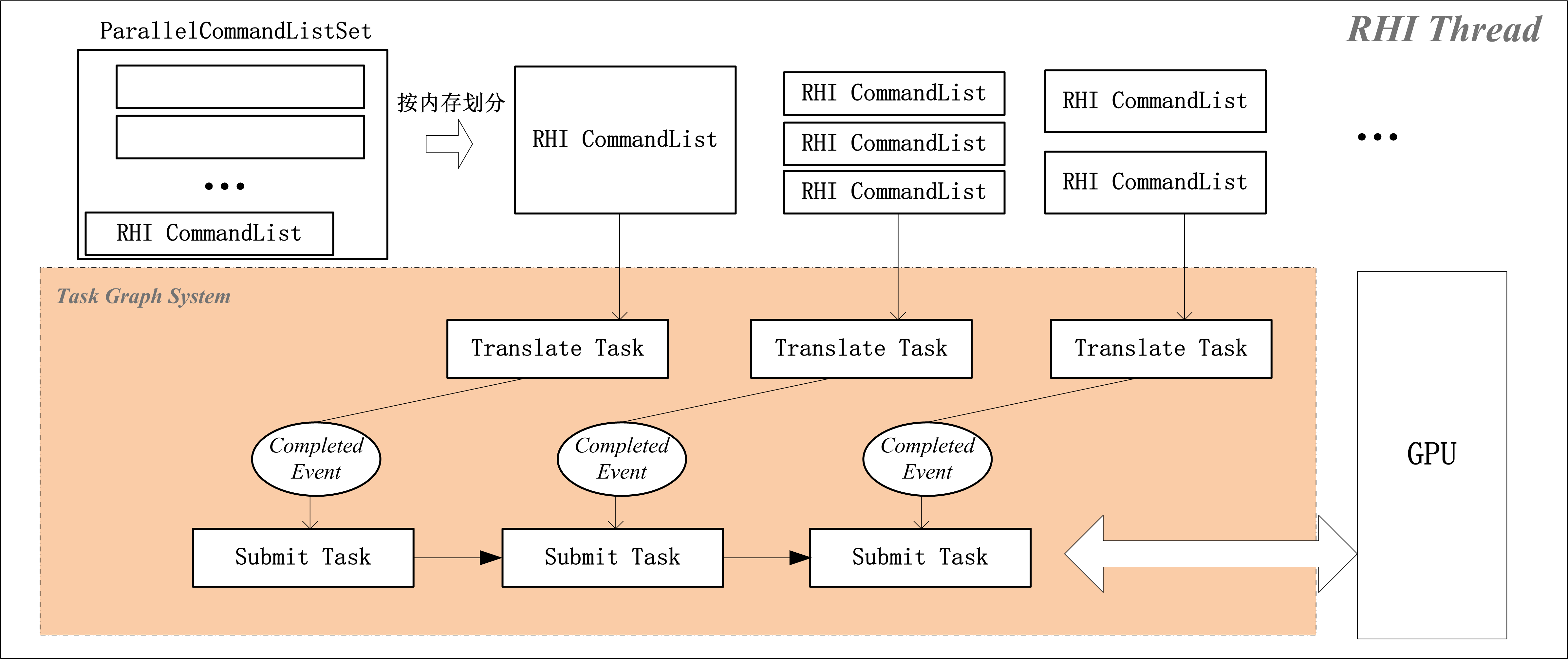
UE有平衡机制,去划分并行任务,指令数太少,虚幻也不会走并行派发。并行渲染可以关注以下类:FParallelTranslateCommandList和FRHICommandWaitForAndSubmitSubListParallel
3.2 渲染指令
UE4通过宏来创建一个渲染指令任务(Task),最终到TaskGraph系统创建若干渲染任务,渲染指令最终直接调用相应渲染平台对应FDynamicRHI的实现,不走并行渲染,如。
#define ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER(TypeName,ParamType1,ParamName1,ParamValue1,Code) \
ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_DECLARE(TypeName,ParamType1,ParamName1,ParamValue1,Code) \
ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_CREATE(TypeName,ParamType1,ParamValue1)
上面这个宏调用另外两个宏,第一个创建Task执行代码,第二个新创建一个Task.
/**
* Declares a rendering command type with 1 parameters.
*/
#define ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_DECLARE_OPTTYPENAME(TypeName,ParamType1,ParamName1,ParamValue1,OptTypename,Code) \
class EURCMacro_##TypeName : public FRenderCommand \
{ \
public: \
EURCMacro_##TypeName(OptTypename TCallTraits<ParamType1>::ParamType In##ParamName1): \
ParamName1(In##ParamName1) \
{} \
TASK_FUNCTION(Code) \
TASKNAME_FUNCTION(TypeName) \
private: \
ParamType1 ParamName1; \
};
#define ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_DECLARE(TypeName,ParamType1,ParamName1,ParamValue1,Code) \
ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_DECLARE_OPTTYPENAME(TypeName,ParamType1,ParamName1,ParamValue1,,Code)
#define ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER_CREATE(TypeName,ParamType1,ParamValue1) \
{ \
LogRenderCommand(TypeName); \
if(ShouldExecuteOnRenderThread()) \
{ \
CheckNotBlockedOnRenderThread(); \
TGraphTask<EURCMacro_##TypeName>::CreateTask().ConstructAndDispatchWhenReady(ParamValue1); \
} \
else \
{ \
EURCMacro_##TypeName TempCommand(ParamValue1); \
FScopeCycleCounter EURCMacro_Scope(TempCommand.GetStatId()); \
TempCommand.DoTask(ENamedThreads::GameThread, FGraphEventRef() ); \
} \
}
在渲染指令的基类中,已经定义了所创建的任务要运行在哪个线程中,且渲染指令任务不存在依赖关系,直接按队列中的顺序执行。
class RENDERCORE_API FRenderCommand
{
public:
// All render commands run on the render thread
static ENamedThreads::Type GetDesiredThread()
{
check(!GIsThreadedRendering || ENamedThreads::RenderThread != ENamedThreads::GameThread);
return ENamedThreads::RenderThread;
}
static ESubsequentsMode::Type GetSubsequentsMode()
{
// Don't support tasks having dependencies on us, reduces task graph overhead tracking and dealing with subsequents
return ESubsequentsMode::FireAndForget;
}
};
如果有注意到,渲染指令内部可以直接访问到一个名为RHICmdList的指令列表,这个列表里的RHI指令用来直接访问硬件接口,
#define TASK_FUNCTION(Code) \
void DoTask(ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionGraphEvent) \
{ \
FRHICommandListImmediate& RHICmdList = GetImmediateCommandList_ForRenderCommand(); \
Code; \
}
通过GetImmediateCommandList_ForRenderCommand取得一个全局的指令列表GRHICommandList.CommandListImmediate。
全局指令列表是不纳入并行派发指令的列表的。
3.3 RHI指令
为了实现并行渲染,UE4引入了RHI线程,渲染指令最终会调用RHI指令最终到GPU上执行。RHI指令调用关系图:
-
渲染指令调用RHICommandList的ImmediateFlush或Flush方法来调用全局指令执行器GRHICommandList(FRHICommandListExecutor)。
-
指令执行器FRHICommandListExecutor调用ExecuteList执行指令列表。
-
RHICommand指令调用对应平台的RHICommandContext方法在GPU中执行。
-
游戏主线程可调用FlushRenderingCommands执行当前所有队列中所有指令,清空一次渲染指令队列。
-
不同的RHI平台对应类:
-
FMetalDynamicRHI: 苹果Metal渲染硬件接口
-
FD3D12DynamicRHI: WindowD3D渲染硬件接口
-
FOpenGLDynamicRHI: OpenGL渲染硬件接口,跨平台API
-
FVulkanDynamicRHI: Vulkan渲染硬件接口,跨平台API,试图取代OpenGL
-
-
在并行渲染中,会新增一个RHIThread,可以关注以下类:FParallelTranslateCommandList,FRHICommandWaitForAndSubmitSubListParallel,FDispatchRHIThreadTask
-
按占用内存大小(GetUsedMemory)来划分并行执行的CommandList集合
3.4 线程同步
为了实现最终渲染效果,需要保证游戏线程、渲染线程及RHI线程的协同关系,UE4最终实现的效果是:
- 游戏线程在执行第N+1帧时,渲染线程可能在执行N或N+1帧,一般情况是渲染线程慢一帧。
- 游戏线程在执行第N+1帧时,RHI线程在转换N或N+1帧的指令,依赖于渲染线程的执行时间。
游戏主线程通过以下方法阻塞等待当前帧渲染线程任务完成:
// ensure the thread has actually started and is idling
FRenderCommandFence Fence;
Fence.BeginFence();
Fence.Wait();
-
BeginFence创建一个TaskGraph系统的空任务(FNullGraphTask),作为完成事件,放入渲染任务线程队列。
-
Wait则阻塞游戏主线程,等待所创建的完成事件。
-
游戏主线程中调用FlushRenderingCommands接口可以阻塞游戏线程,主动执行当前所有队列中所有指令,清空一次渲染指令队列。
通过FRenderCommandFence类可以实现主线程阻塞等待,进而UE4通过以下方式实现线程同步:
-
游戏主线程的TickLoop中使用FFrameEndSync来实现线程同步,在帧末调用以下代码:
static FFrameEndSync FrameEndSync; static auto CVarAllowOneFrameThreadLag = IConsoleManager::Get(). FindTConsoleVariableDataInt(TEXT("r.OneFrameThreadLag")); FrameEndSync.Sync( CVarAllowOneFrameThreadLag->GetValueOnGameThread() != 0 ); -
FFrameEndSync中使用两个FRenderCommandFence来实现同步,之所以和两个Fence是为了可以有一帧的延迟,可以选择完成同步或一帧延迟同步,同步逻辑在其Sync函数中实现(默认情况下游戏线程比渲染线程快一帧,官方表述为“single frame behind” renderer)。
/** * Syncs the game thread with the render thread. Depending on passed in bool this will be a total * sync or a one frame lag. */ void FFrameEndSync::Sync( bool bAllowOneFrameThreadLag ) { check(IsInGameThread()); Fence[EventIndex].BeginFence(); bool bEmptyGameThreadTasks = !FTaskGraphInterface::Get().IsThreadProcessingTasks(ENamedThreads::GameThread); if (bEmptyGameThreadTasks) { // need to process gamethread tasks at least once a frame no matter what FTaskGraphInterface::Get().ProcessThreadUntilIdle(ENamedThreads::GameThread); } // Use two events if we allow a one frame lag. if( bAllowOneFrameThreadLag ) { EventIndex = (EventIndex + 1) % 2; } Fence[EventIndex].Wait(bEmptyGameThreadTasks); // here we also opportunistically execute game thread tasks while we wait } -
渲染指令在TaskGraph系统中形成是一个队列结构(非图结构),所以在帧末添加一个完成任务一定是在渲染指令任务队列的最后,即该任务完成则表明当前帧的渲染指定都已经完成。
-
对于RHI线程,因为它依赖于渲染线程,当前所处理的指令所在帧依赖于渲染线程,在帧末也会清空RHI指令队列。
// end of RHI frame ENQUEUE_UNIQUE_RENDER_COMMAND(EndFrame, { RHICmdList.EndFrame(); GPU_STATS_ENDFRAME(RHICmdList); RHICmdList.PopEvent(); });
备注:运行时,RHI线程直接引用编译完成的Shader字节码,在不同平台下执行。 Shader = RHICreatePixelShader(UncompressedCode);
4 Shader编译
UE与Unity类似, 将HLSL转化为GLSL实现跨平台。UE的HLSL 交叉编译器 将 高级着色语言 (HLSL) 着色器源代码编译成高级中间表示法,执行独立于设备的优化,并生成 OpenGL 着色语言 (GLSL) 兼容源代码。
Shader编译的目标将Shader编译为可移植字节码, 图形驱动程序将采用此字节码并将其再次编译为GPU指令以应用。
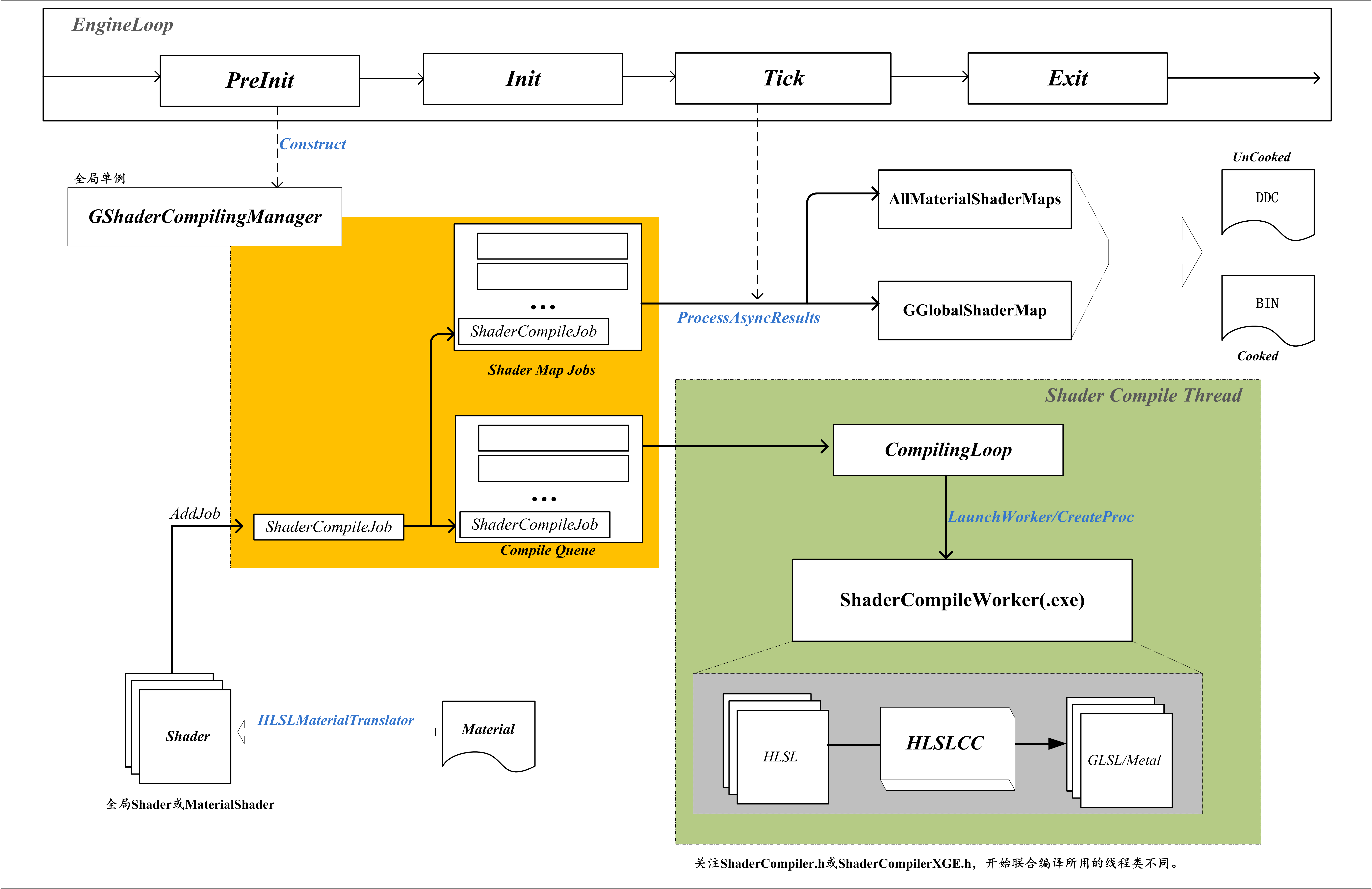
-
虚幻有一个全局Shader编译管理类:GShaderCompilingManager,用于管理所有Shader的编译工作。在FEngineLoop::PreInit中创建,在FEngineLoop::AppPreExit中销毁,管理类中CompileQueue队列用于存储待编译的任务。
-
引擎启动时或材质变化时,通过GShaderCompilingManager的AddJobs方法将新的编译任务放入CompileQueue,同步存储到ShaderMapJobs中,包含材质Shader与全局Shader。
-
材质需要先通过HLSLMaterialTranslator转换为HLSL Shader, 关注FMaterialShaderMap::Compile方法。
-
对于Shader编译任务,由一个独立的Shader编译线程来完成,即FShaderCompileThreadRunnable,联合编译条件下是FShaderCompileXGEThreadRunnable_XmlInterface。
-
Shader编译线程可以访问到全局材质管理类,编译线程一直处理循环检测状态,会取GShaderCompilingManager的CompileQueue队列中的任务执行编译。
-
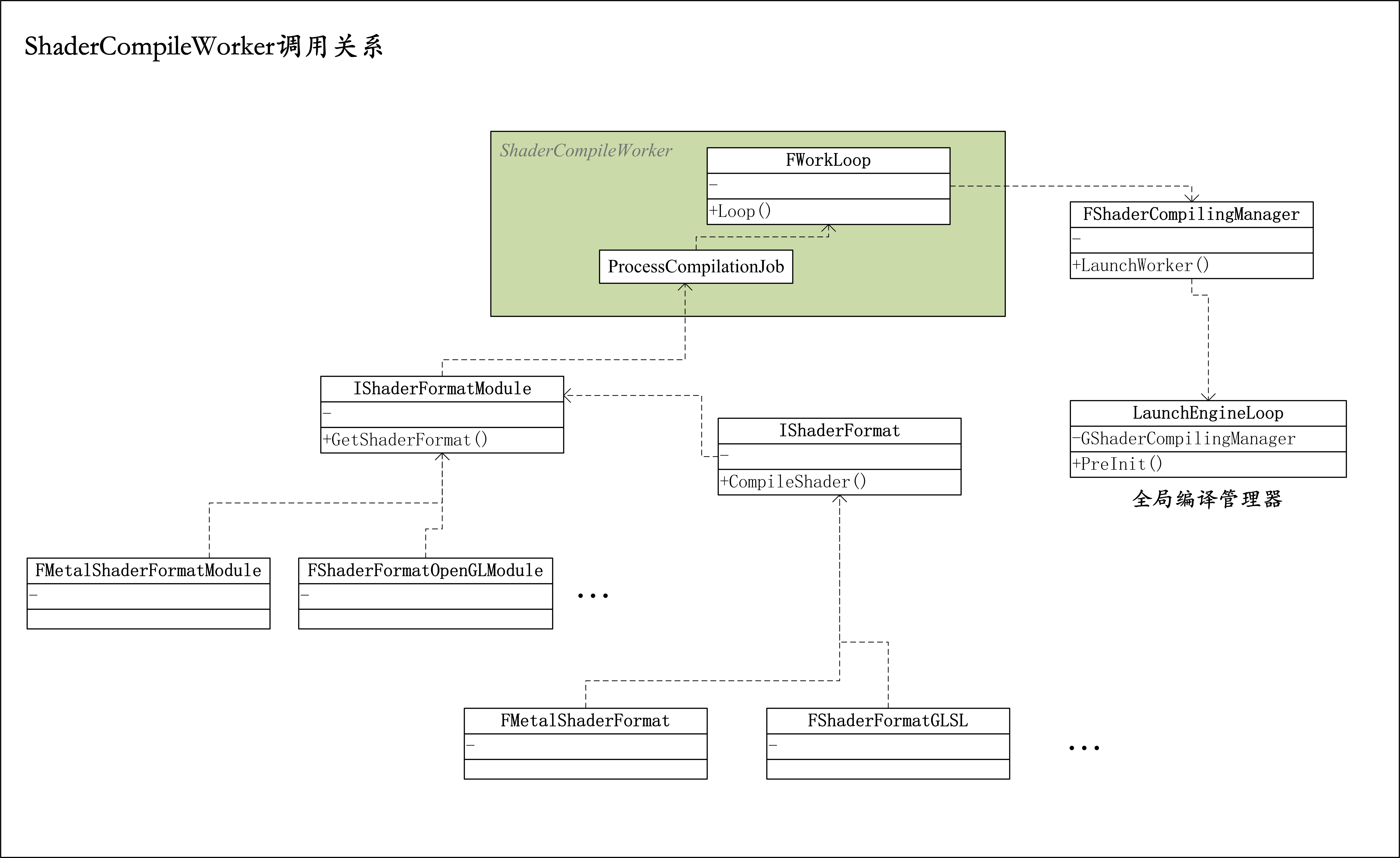
Shader编译线程会单独拉起ShaderCompileWorker来完成编译任务,各平台的Shader编译由IShaderFormat派生:
FShaderCompilingManager* GShaderCompilingManager = NULL; FShaderCompilingManager::FShaderCompilingManager() : bCompilingDuringGame(false), NumOutstandingJobs(0), #if PLATFORM_MAC ShaderCompileWorkerName(TEXT("../../../Engine/Binaries/Mac/ShaderCompileWorker")), #elif PLATFORM_LINUX ShaderCompileWorkerName(TEXT("../../../Engine/Binaries/Linux/ShaderCompileWorker")), #else ShaderCompileWorkerName(TEXT("../../../Engine/Binaries/Win64/ShaderCompileWorker.exe")), #endif SuppressedShaderPlatforms(0) { ... } -
ShaderCompileWorker的类关系如下。
-
当材质变化时,打开任务管理器,就可以查看到一个独立的Shader编译程序在执行。
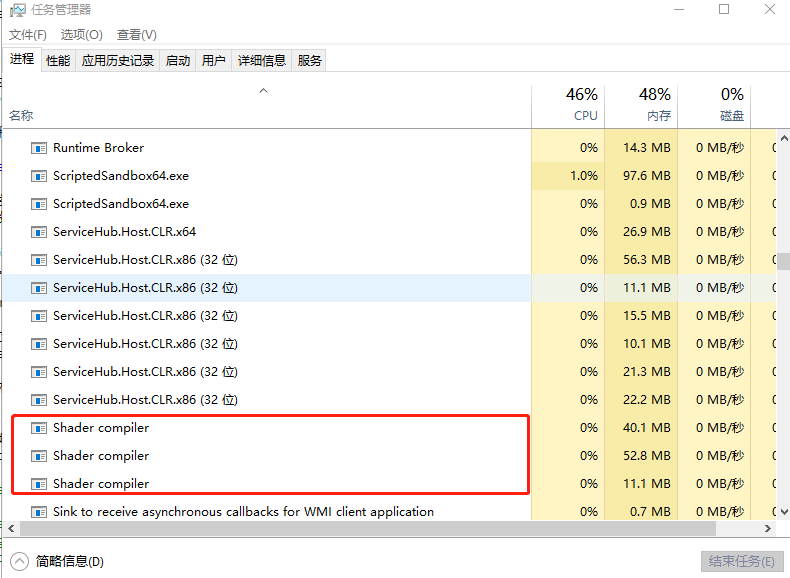
-
Shader交叉编译的目标是把HLSL Shader代码转换成各平台的Shader字节码,参考HLSLCC交叉编译,**注意只有在打包或编辑器启动时会执行转换,运行时调用
HLSLCC的转化流程,是HLSL->AST->IR->GLSL/Metal + ParameterMap。
-
材质编译任务会被同步放入ShaderMapJobs列表中,然后每帧GShaderCompilingManager的ProcessAsyncResults方法中会去取对应编译完成的结果,并在ProcessCompiledShaderMaps函数中处理。运行时,会把编译的材质Shader放入AllMaterialShaderMaps中,全局Shader放入GGlobalShaderMap中。
-
最后,调用ProcessCompilationResults方法,执行SaveToDerivedDataCache方法存储字节码到DDC中,UE4编辑器下,Shader编译完会被存储在引擎目录的DerivedDataCache目录下。打包时,材质Shader的编译结果会被直接打包到材质所在的Package里,全局Shader会单独存储,这样可以方便在引擎启动的时候加载全局Shader。DDC存储的配置可以在BaseEngine.ini中查询到([DerivedDataBackendGraph]),搜索DerivedDataCache关键字即可看到不同环境下的DDC配置,自定义修改可以参考官方文档关于Derived Data Cache的描述。
-
最后给出Shader编译过程的详细类调用关系,如下。
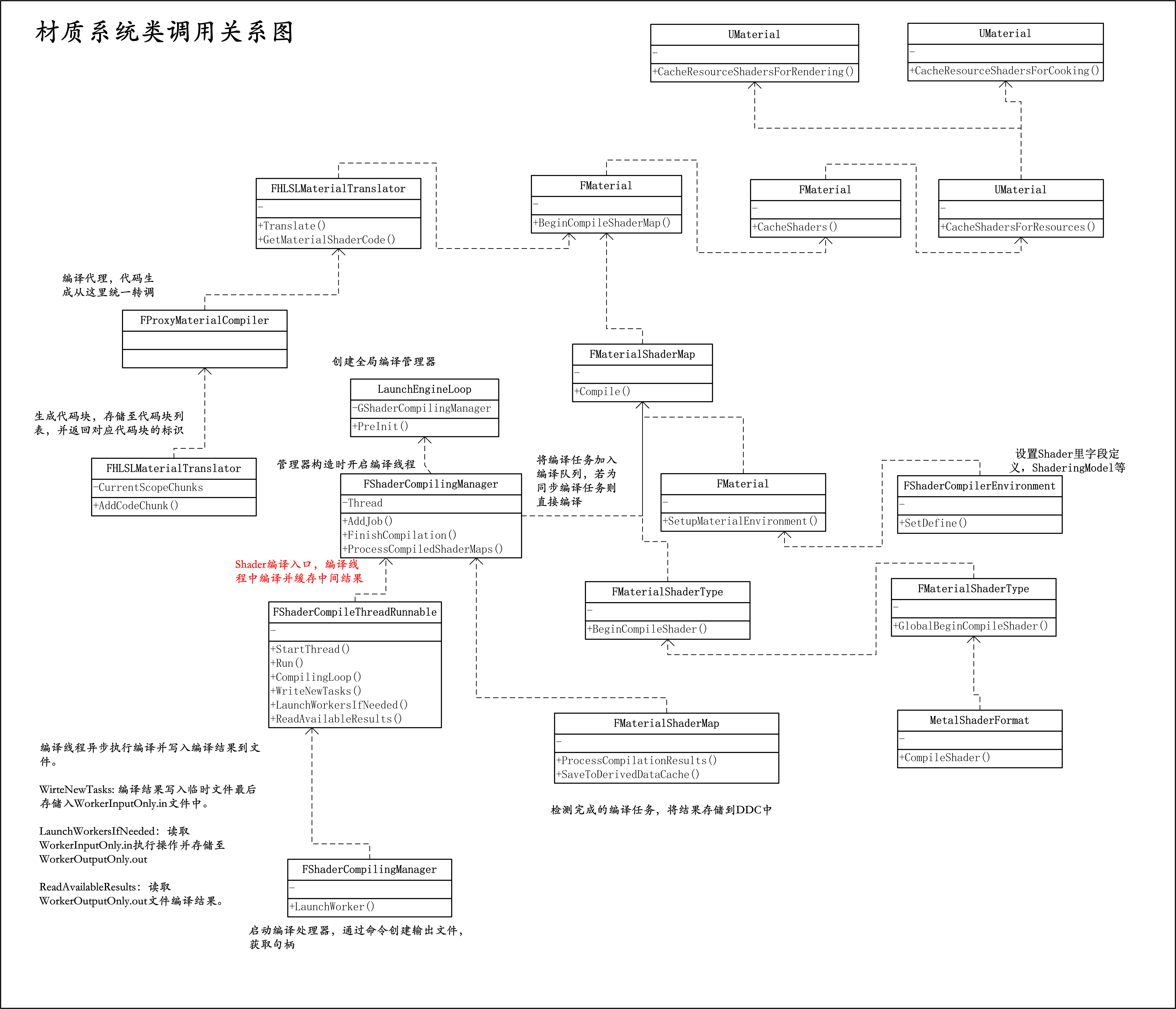
-
运行时,会为每个Shader生成对应的FShaderResource实例,每个平台的RHI类的Init初始化时会调用FRenderResource::GetResourceList函数可以获取全局所有的Shader链表(FRenderResource为FShaderResource基类),调用FShaderResource::InitRHI()函数中会各平台接口加载顶点和片元Shader,至此,便完成了Shader的编译与加载流程。
-
不同的RHI平台对应类: FMetalDynamicRHI: 苹果Metal渲染硬件接口; FD3D12DynamicRHI: WindowD3D渲染硬件接口; FOpenGLDynamicRHI: OpenGL渲染硬件接口,跨平台API; FVulkanDynamicRHI: Vulkan渲染硬件接口,跨平台API,试图取代OpenGL
参考
- OpenGL中Shader的使用
- Understand UE4 Multi-thread Rendering with three pictures
- UE4渲染模块分析
- UE4 PBR Shading Model
- Real Shading in Unreal Engine 4
- 模板测试(stencil testing)
- 深度测试
- OpenGL中的Alpha测试,深度测试,模板测试,裁减测试
- 《Exploring in UE4》多线程机制详解
- UE4里的渲染线程
- UE4 Shader Development
- UE4 Derived Data Cache
- 延迟渲染
- Compiling Shaders Manually
- UE4渲染代码逻辑总结